OCR 画像から日本語抽出設定
はじめに
BizRobo! のOCR(光学文字認識)機能は、「Tesseract」と「OmniPage」の2つのエンジンを提供しています。デフォルトの「Tesseract OCR」は英語のみ対応ですが、日本語を含む多言語対応には「OmniPage OCR」エンジンへの切り替えが必要です。
また、OCR機能は以下の2つの環境で使用できます。
- DS の組み込みブラウザ(Chromium)
- DAS インストール端末
本セクションでは、OCR機能で日本語抽出を可能にする2種の設定方法を説明します。
参考 「OCR機能とエンジンの特徴について」
OCR機能の特徴
- 画像ファイルからテキストデータを自動抽出
- 2つのエンジンが選択可能(Tesseract または OmniPage)
- 複数言語対応(ISO 639-3またはISO 639-1形式の言語コードを使用)
- フォントサイズに応じた認識設定が可能
OCRエンジンの特徴について
-
Tesseract(デフォルト)
- BizRobo! では、デフォルトで英語がインストールされている
- 印刷文字の高精度認識
- 画像の二値化と閾値デルタ設定を手動調整が可能
-
OmniPage
- 多言語対応(120以上の言語をサポート(日本語、中国語を含む))
- 複雑なレイアウトや多様なフォントに対応(印刷された文字と手書き印刷体を認識)
- 「コンピュータビジョン1と機械学習を組み合わせた先進的な画像処理技術(自動回転、傾き補正、ノイズ除去などを自動実行)
設定手順
1. DS(Chromium)で画像から日本語抽出をする設定
DAS を使用せず、DSのロボットの内で OCR機能「画像からテキスト抽出」ステップで日本語を画像から抽出する場合は、ocr.cfg ファイルの エンジンタイプをデフォルト設定の「Tesseract (デフォルト)」から「OmniPage」に変更する必要があります。
-
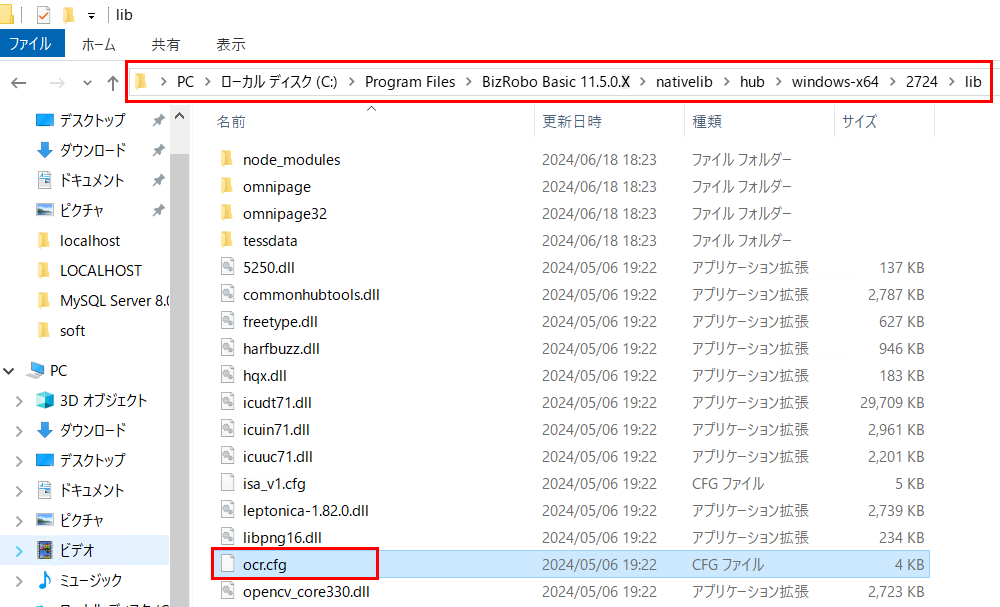
エンジンタイプを OmniPage に変更します。RS実行環境で、以下の ocr.cfg ファイルをテキストエディタで開きます。
例:
警告
- <ビルド番号>は、お使いのバージョンによって異なります。
- ocr.cfgファイルは、バックアップを事前に行ってください。
-
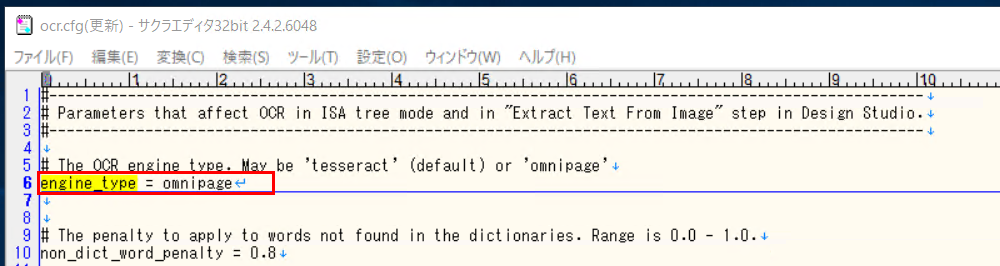
ocr.cfg 内で「engine_type」をテキスト検索します。
engine_type = omnipage となるように、 "tesseract" 箇所を "omnipage" に修正します。
-
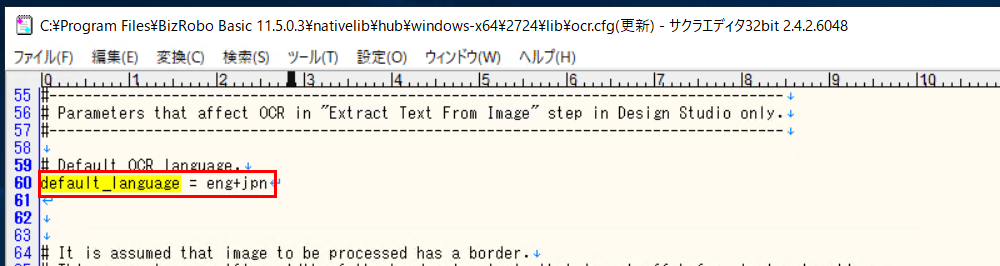
OCR抽出言語に日本語を追加します。ocr.cfg 内で「default_language」をテキスト検索します。
default_language = eng+jpn になるように、 "+jpn" を追加します。
-
ファイルを上書き保存します。
以上で DS の Chromium で画像から日本語抽出する設定は完了です。
2. DASで画像から日本語抽出をする設定
注意
DAS の OCR エンジンと言語設定は、DAS インストール端末毎に設定してください。
-
DAS設定を開きます。通知領域で DAS アイコンを右クリックし、[設定] をクリックします。

DAS設定が起動します。
-
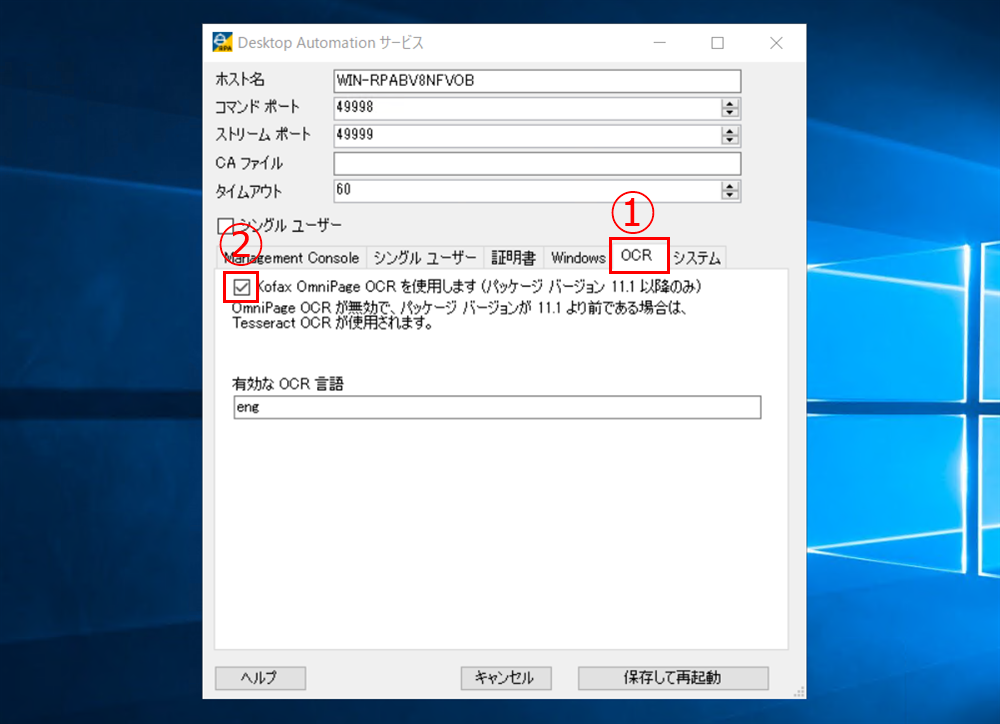
DAS設定 >[OCR] タブをクリックします。[Kofax OmniPage OCR を使用します]をクリックし、チェックをつけます。
-
「英語」のみの抽出設定に「日本語」を追加します。[有効なOCR言語] 入力ボックスが eng+jpn になるように "+jpn" を追加します。
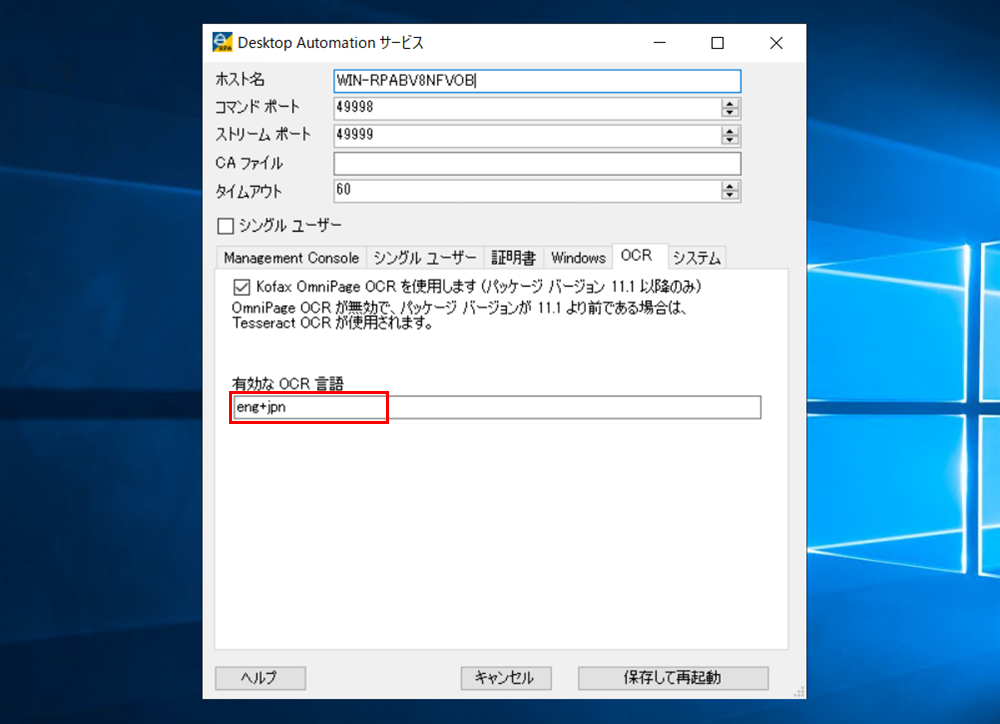
-
[保存して再起動]をクリックします。
以上でDASで画像から日本語抽出する設定は完了です。
作業完了確認
OCR設定が正しく適用されたことを確認するために、以下の手順を実行してください。環境に応じてタブを選択してください。
DS(Chromium)で画像から日本語抽出確認
DSの組み込みブラウザ(Chromium)で、画像から日本語の文字が抽出できるか確認します。
-
DSを起動します。マイプロジェクトの任意のプロジェクトフォルダの上で右クリック >[新規作成]>[ロボット]をクリックします。
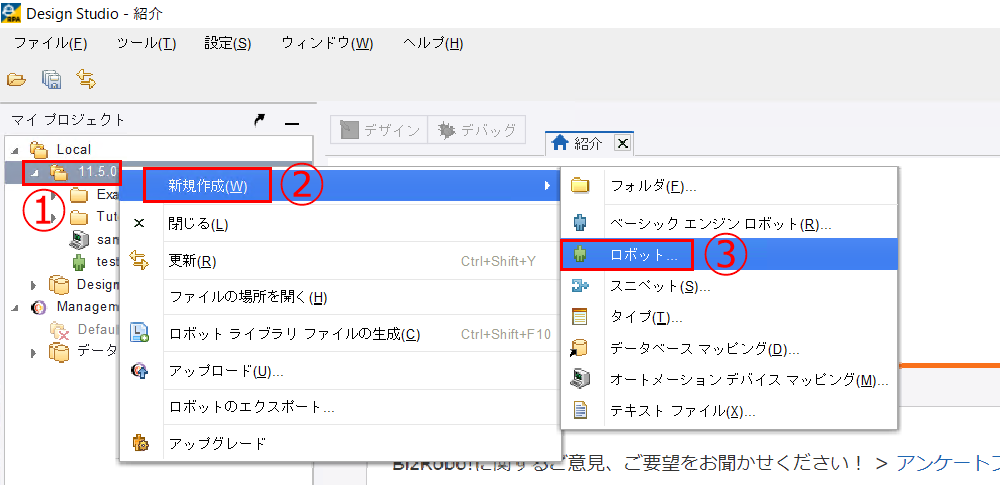
ポップアップで「新しいロボット」画面が表示されます。
-
新しいロボット画面でロボット名(任意)を入力します。(本書では「ocr.robot」とします。) [終了] をクリックします。
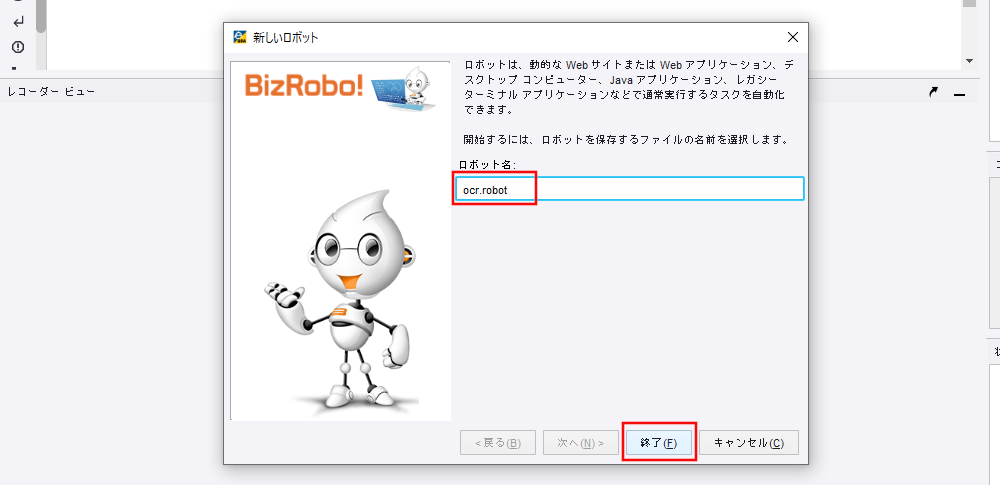
ロボットエディター(chromium)が開きます。
-
ocrで抽出したテキストを格納する変数 (タイプ:Text)を作成します。ロボットエディター >[(x)] (ロボット定義ツールバー変数アイコン)」をクリックします。

ロボット定義ツールバーが開きます。[変数を追加]をクリックします。
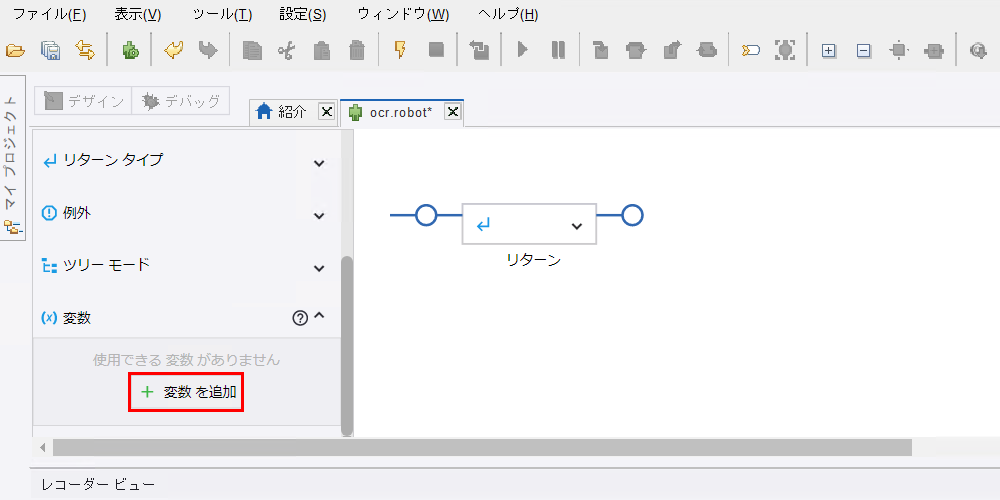
-
変数の名前(任意)を入力します。ここでは、
read_ocrとします。Enterを押します。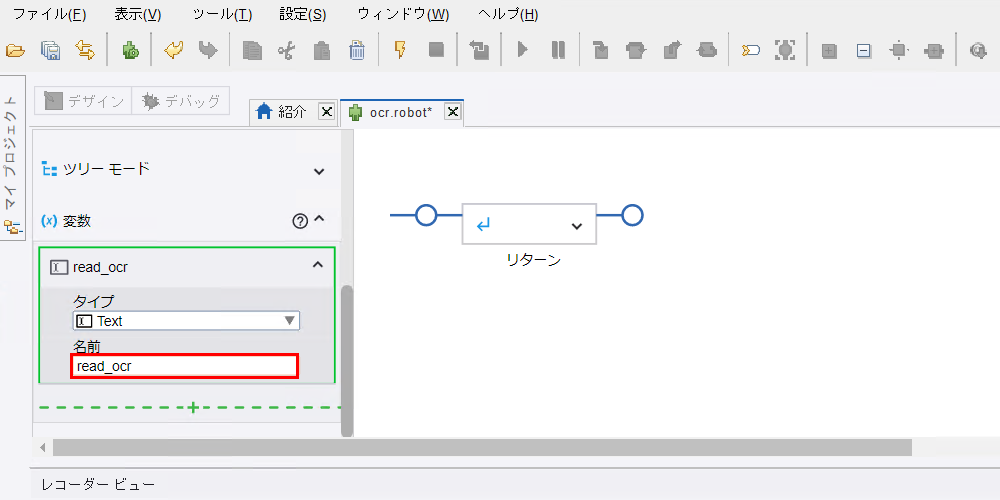
-
フローポイントを右クリックし、[アプリケーション]>[参照] をクリックします。
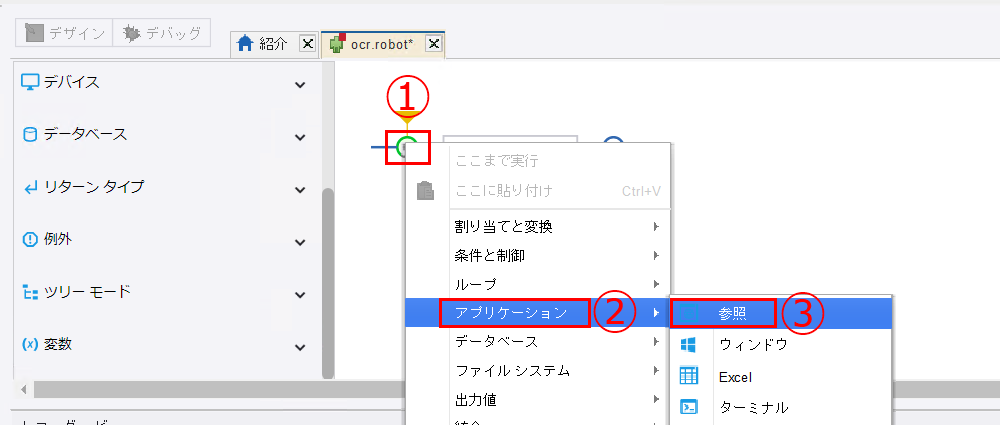
-
「参照ステップ] 内のアプリケーション名に任意の名前(例:
site)を入力します。URL入力欄に以下「OCR確認用WEBページのURL」を貼り付けます。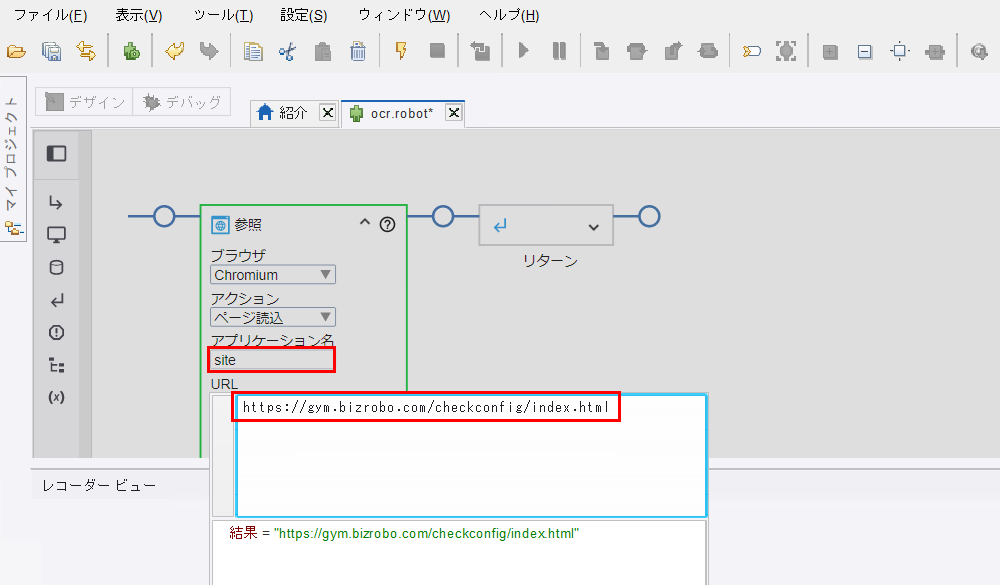
-
ツールバーにある [実行] をクリックします。

[ステップオーバー] をクリックします。

参照ステップが実行され、レコーダービューに「OCR確認用WEBページ」が表示されます。※必要に応じ、レコーダービューの拡大縮小やウィンドウを調整します。
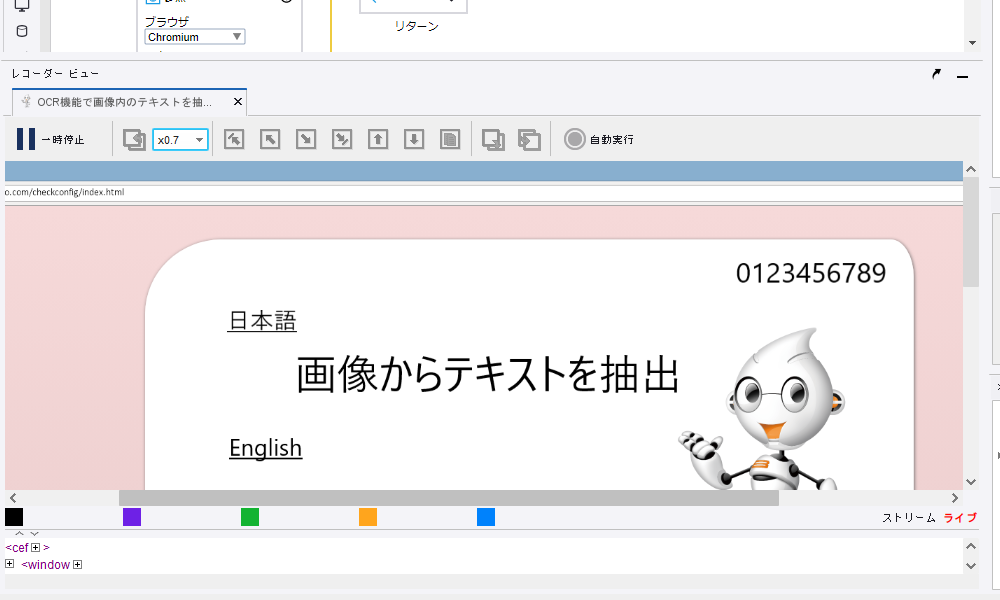
-
ページ内にある画像内の文字列「画像からテキストを抽出」をマウスドラックで囲みます。紫色の枠で文字列が囲まれます。
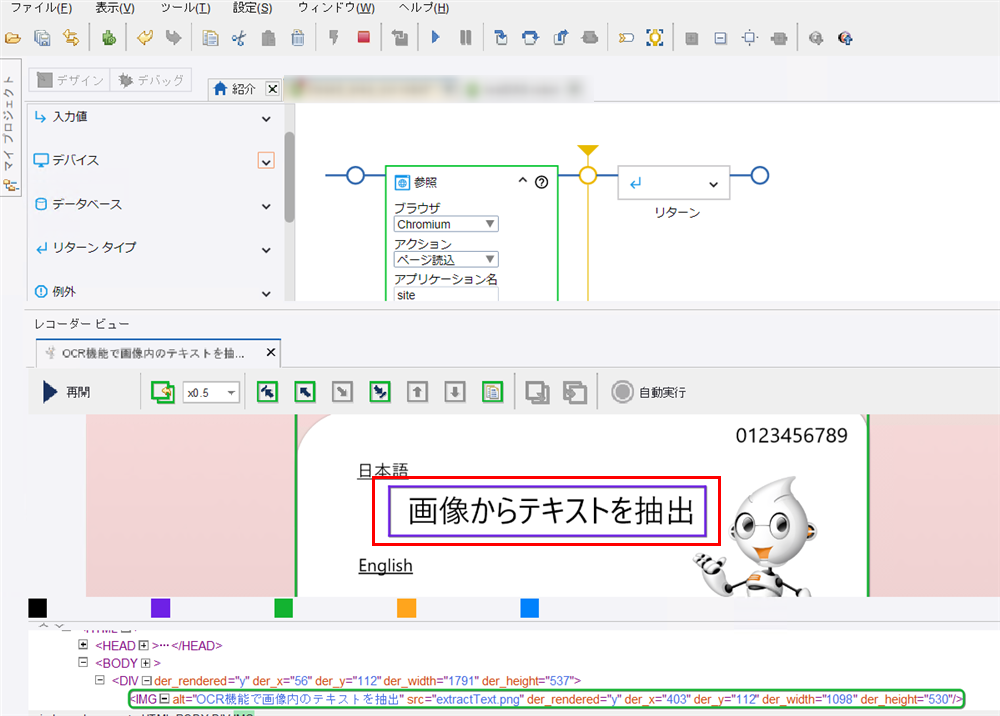
参考
ウェブページのツリービュー(上記画像の最下部、緑枠)には、画像を示す「IMG」タグと、画像説明の「alt」属性が表示されます。alt属性は構造化情報のため、プログラム(「値を抽出」ステップ)で取得可能です。一方、画像内のテキストは「人間」は文字と認識できますが、プログラムは認識できません。そのため、ツリービューに表示されず、これらのテキストを抽出するには AI OCR 技術が必要になります。
-
紫色の枠内で右クリックします。メニューが表示されたら、[画像からテキストを次へ抽出]>[<作成した変数 本書では read_ocr>:Text]をクリックします。
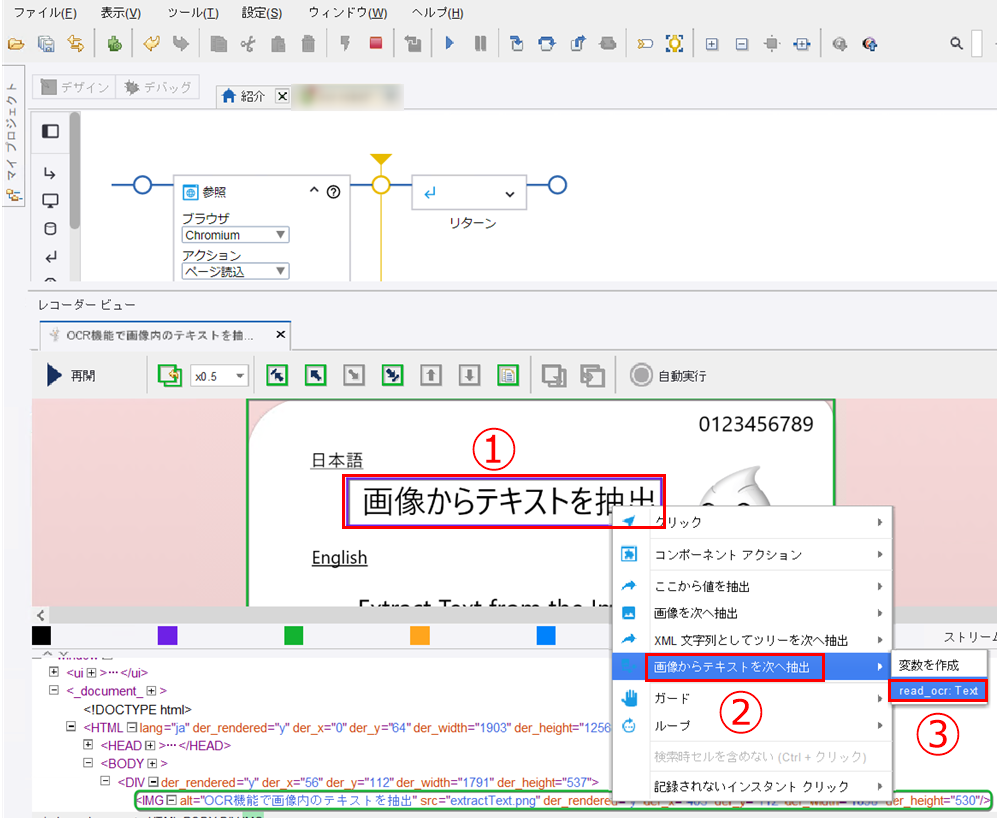
-
[ステップオーバー]をクリックします。
-
画面右下の 状態 > 変数 > ▶ (右向き三角) をクリックします。 変数 read_ocr に「画像からテキストを抽出」が表示され、画像から日本語抽出がされていることを確認します。
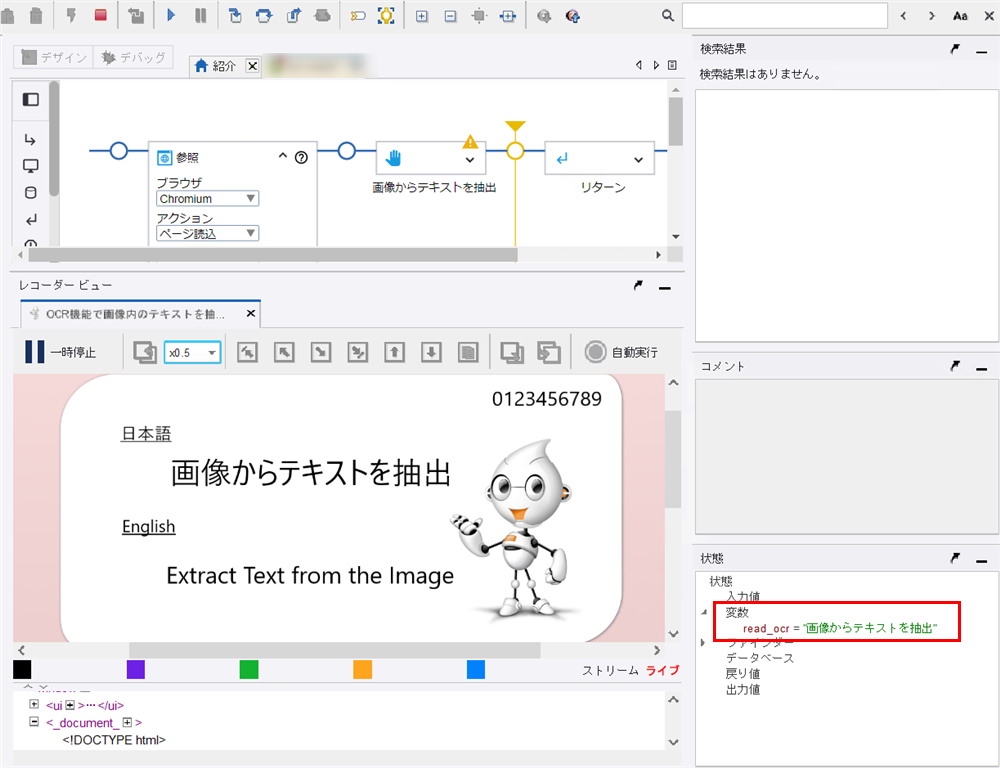
以上で、DS(Chromium)による画像からの日本語抽出確認は完了です。
DASで画像から日本語抽出確認
-
インターネット接続環境で、DASインストール端末に、以下OCR確認用のWebページ一式をダウンロードします。任意の場所にzipを展開をします。(本書ではデスクトップに展開します。)
- 閉域環境 OCR確認用 WEBページ一式
-
DSを起動します。DASの構築 > DASとDSの接続確認で作成した「testDAS.robot」をダブルクリックします。
testDAS.robotがロボットビューに表示されます。
-
ocrで抽出したテキストを格納する変数 (タイプ:Text)を作成します。ロボットエディター >[(x)] (ロボット定義ツールバー変数アイコン)」をクリックします。
ロボット定義ツールバーが開きます。[変数を追加]をクリックします。
-
任意の変数の名前を入力します。ここでは、
read_ocrとします。Enterを入力します。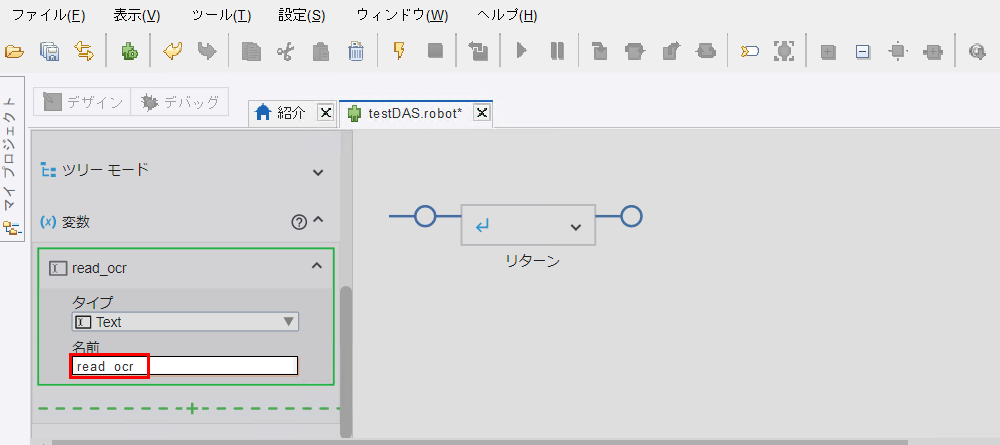
-
フローポイントを右クリックし、[アプリケーション]>[参照] をクリックします。
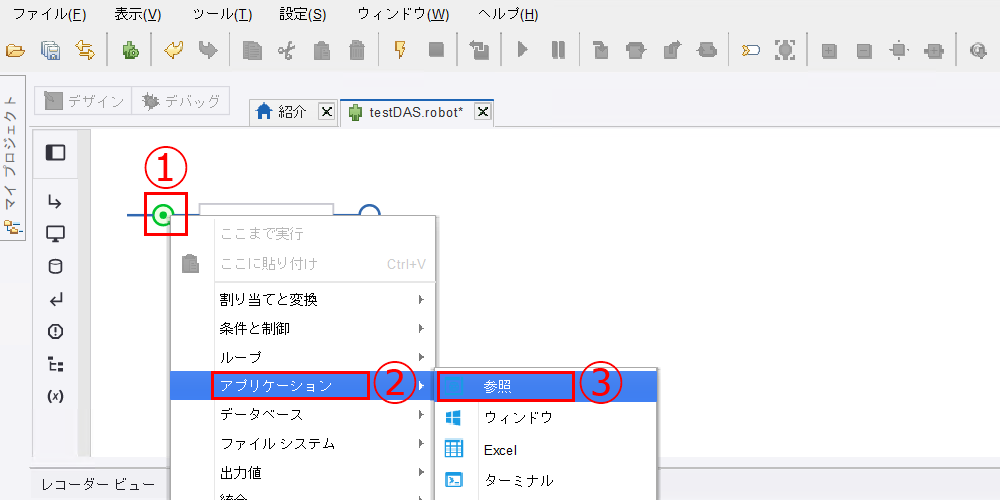
-
OCR確認用 WEBページ一式フォルダ内にある index.html のパスをコピー2します。[参照ステップ] 内のアプリケーション名に任意の名前(例:
site)を入れます。URL入力欄にコピーしたパスを貼り付けます。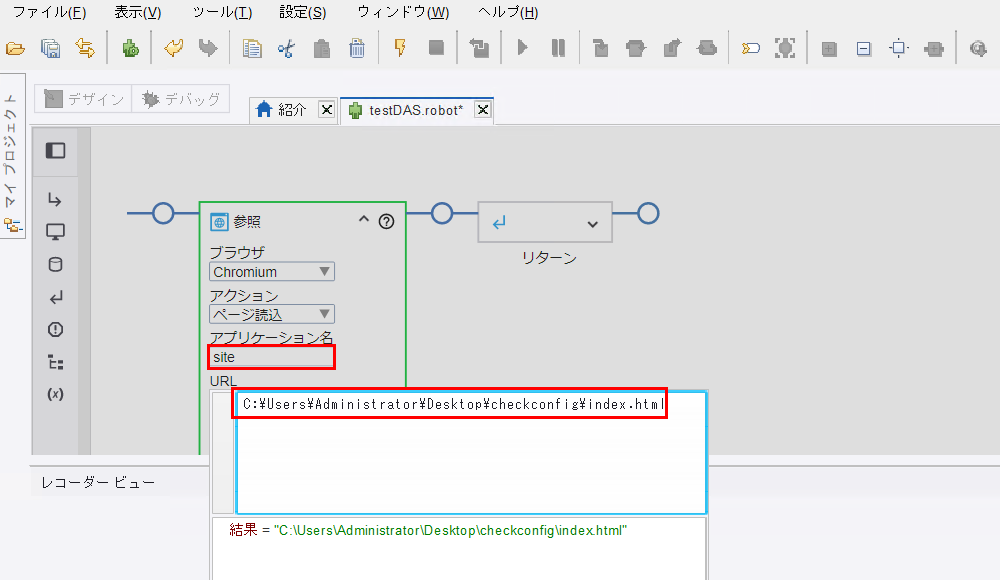
-
ツールバーにある [実行] をクリックします。
[ステップオーバー] をクリックします。
参照ステップが実行され、レコーダービューに「OCR確認用WEBページ」が表示されます。※必要に応じ、レコーダービューの拡大縮小やウィンドウを調整します。
-
ページ内にある画像内の文字列「画像からテキストを抽出」をマウスドラックで囲みます。紫色の枠で文字列が囲まれます。
-
紫色の枠内で右クリックします。メニューが表示されたら、[画像からテキストを次へ抽出]>[<作成した変数 本書では read_ocr>:Text]をクリックします。
-
[ステップオーバー]をクリックします。
-
画面右下の 状態 > 変数 > ▶ (右向き三角) をクリックします。 変数 read_ocr に「画像からテキストを抽出」が表示され、画像から日本語抽出がされていることを確認します。
以上で、DASによる画像からの日本語抽出確認は完了です。
DS(Chromium)で画像から日本語抽出確認
-
インターネット接続環境で、DSインストール端末に、以下OCR確認用のWebページ一式をダウンロードし、任意の場所にzipを展開をします。(本書ではデスクトップに展開します。)
-
DSを起動します。マイプロジェクトの任意のプロジェクトフォルダの上で右クリック >[新規作成]>[ロボット]をクリックします。
ポップアップで「新しいロボット」画面が表示されます。
-
新しいロボット画面でロボット名(任意)を入力します。(本書では「ocr.robot」とします。) [終了] をクリックします。
ロボットエディター(chromium)が開きます。
-
ocrで抽出したテキストを格納する変数 (タイプ:Text)を作成します。ロボットエディター >[(x)] (ロボット定義ツールバー変数アイコン)」をクリックします。
ロボット定義ツールバーが開きます。[変数を追加]をクリックします。
-
変数の名前(任意)を入力します。ここでは、
read_ocrとします。Enterを押します。
-
フローポイントを右クリックし、[アプリケーション]>[参照] をクリックします。
-
閉域環境 OCR確認用 WEBページ一式 を展開した「WEBページ一式」フォルダ内にある index.html のパスをコピー2します。 [参照ステップ] 内のアプリケーション名に任意の名前(例:
site)を入れます。URL入力欄にコピーしたパスを貼り付けます。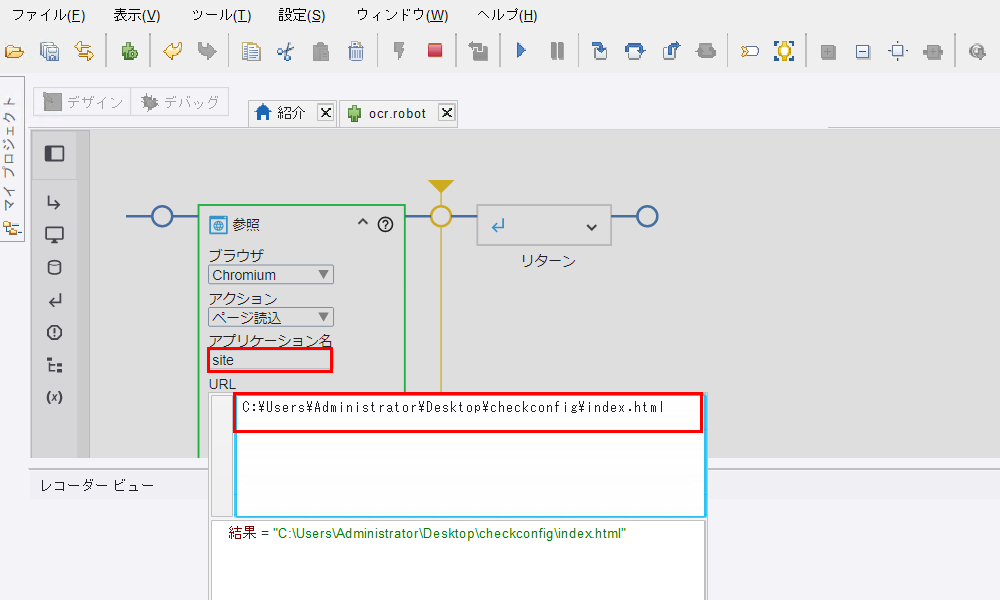
-
ツールバーにある [実行] をクリックします。
[ステップオーバー] をクリックします。
参照ステップが実行され、レコーダービューに「OCR確認用WEBページ」が表示されます。※必要に応じ、レコーダービューの拡大縮小やウィンドウを調整します。
-
ページ内にある画像内の文字列「画像からテキストを抽出」をマウスドラックで囲みます。紫色の枠で文字列が囲まれます。
参考
ウェブページのツリービュー(上記画像の最下部、緑枠)には、画像を示す「IMG」タグと、画像説明の「alt」属性が表示されます。alt属性は構造化情報のため、プログラム(「値を抽出」ステップ)で取得可能です。一方、画像内のテキストは「人間」は文字と認識できますが、プログラムは認識できません。そのため、ツリービューに表示されず、これらのテキストを抽出するには AI OCR 技術が必要になります。
-
紫色の枠内で右クリックします。メニューが表示されたら、[画像からテキストを次へ抽出]>[<作成した変数 本書では read_ocr>:Text]をクリックします。
-
[ステップオーバー]をクリックします。
-
画面右下の 状態 > 変数 > ▶ (右向き三角) をクリックします。 変数 read_ocr に「画像からテキストを抽出」が表示され、画像から日本語抽出がされていることを確認します。
以上で、DS(Chromium/閉域環境)による画像からの日本語抽出確認は完了です。
DASで画像から日本語抽出確認
-
インターネット接続環境で、DASインストール端末に、以下OCR確認用のWebページ一式をダウンロードします。任意の場所にzipを展開をします。(本書ではデスクトップに展開します。)
- 閉域環境 OCR確認用 WEBページ一式
-
DSを起動します。DASの構築 > DASとDSの接続確認で作成した「testDAS.robot」をダブルクリックします。
testDAS.robotがロボットビューに表示されます。
-
ocrで抽出したテキストを格納する変数 (タイプ:Text)を作成します。ロボットエディター >[(x)] (ロボット定義ツールバー変数アイコン)」をクリックします。
ロボット定義ツールバーが開きます。[変数を追加]をクリックします。
-
任意の変数の名前を入力します。ここでは、
read_ocrとします。Enterを入力します。
-
フローポイントを右クリックし、[アプリケーション]>[参照] をクリックします。
-
OCR確認用 WEBページ一式フォルダ内にある index.html のパスをコピー2します。[参照ステップ] 内のアプリケーション名に任意の名前(例:
site)を入れます。URL入力欄にコピーしたパスを貼り付けます。
-
ツールバーにある [実行] をクリックします。
[ステップオーバー] をクリックします。
参照ステップが実行され、レコーダービューに「OCR確認用WEBページ」が表示されます。※必要に応じ、レコーダービューの拡大縮小やウィンドウを調整します。
-
ページ内にある画像内の文字列「画像からテキストを抽出」をマウスドラックで囲みます。紫色の枠で文字列が囲まれます。
-
紫色の枠内で右クリックします。メニューが表示されたら、[画像からテキストを次へ抽出]>[<作成した変数 本書では read_ocr>:Text]をクリックします。
-
[ステップオーバー]をクリックします。
-
画面右下の 状態 > 変数 > ▶ (右向き三角) をクリックします。 変数 read_ocr に「画像からテキストを抽出」が表示され、画像から日本語抽出がされていることを確認します。
以上で、DAS(閉域環境)による画像からの日本語抽出確認は完了です。
作業完了確認チェック
- 画像から日本語を抽出できた
以上で、OCRでの日本語抽出設定及び、設定確認は完了です。
-
コンピュータビジョンとは、機械学習とニューラルネットワークを使用して、デジタル画像、ビデオ、その他の視覚入力から意味のある情報を導き出し、欠陥や問題を見つけたときに推奨事項を作成したり、アクションを実行したりするようにコンピューターやシステムが学習する人工知能(AI)の分野 (引用元:IBM What is computer vision?) ↩
-
対象ファイルの上でShiftを押しながら右クリックします。メニューに[パスのコピー]が表示されますのでクリックします。パスがコピーされます。 ↩↩↩